
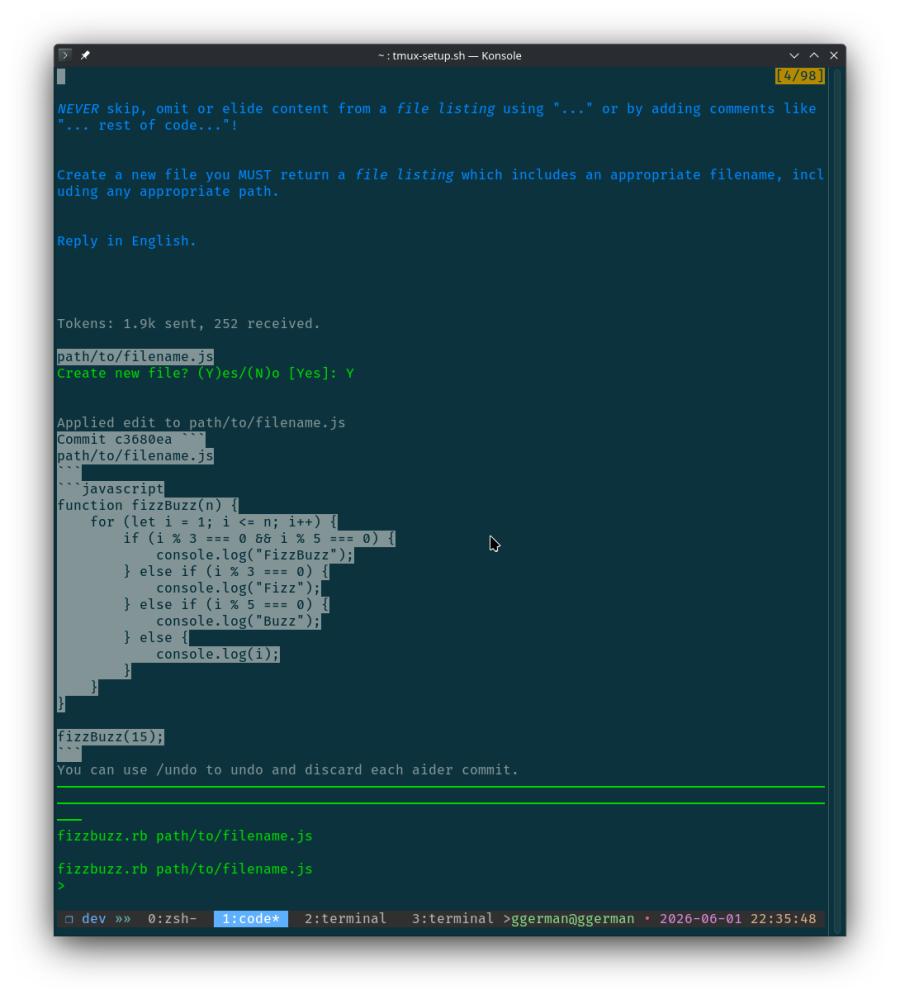
For the last few weeks, I have been experimenting with local AI models to help me develop and maintain Ruby projects.
The goal sounded simple enough.
I wanted an assistant capable of understanding Ruby, Ruby on Rails, Ruby-LibGD, Ruby-GIS, and a collection of libraries and projects that I have worked on over the years.
Like many developers exploring local AI, I started downloading models, testing embeddings, building RAG pipelines, and indexing documentation.
At first, everything looked promising.
The models could answer basic questions.
They could generate small scripts.
They could explain simple algorithms.
But as soon as I moved beyond toy examples and into real-world codebases, the limitations became impossible to ignore.
The Original Sin
I started thinking about model training as a kind of original sin.
Not in a moral sense, but as a permanent mark left on every model at birth.
A model is fundamentally shaped by its training data.
The larger the dataset, the broader its knowledge.
The more examples it has seen, the better it can generalize.
But every model carries the fingerprints of its training forever.
No matter how much context you provide later, you are still working with the same underlying neural network.
This became obvious when working with Ruby-specific libraries.
A model may have seen millions of examples of Python.
Millions of examples of JavaScript.
Millions of examples of C++.
But how many examples of Ruby-LibGD has it actually seen?
How many examples of MapView?
How many examples of custom GIS rendering code written by a handful of developers?
The answer is usually: not many.
The model was never born into that world.
The Promise of RAG
The obvious answer is RAG.
Retrieval-Augmented Generation has become the standard recommendation whenever a model lacks domain knowledge.
Need more information?
Add documents.
Need more accuracy?
Add documentation.
Need project-specific knowledge?
Add embeddings.
Need understanding of proprietary code?
Build a vector database.
In theory, this solves the problem.
The model receives relevant information before generating its response.
And to some extent, it works.
RAG absolutely improves answers.
A model that knows nothing about a project can suddenly discuss classes, methods, APIs, and documentation that were never part of its original training.
But there is an important distinction.
RAG provides information.
It does not provide skill.
The Karate Master and the Singer
Imagine a karate master.
Now give him a library full of books about singing.
He can read them.
He can quote them.
He can explain vocal exercises.
He can discuss music theory.
He can summarize techniques.
But that does not make him a singer.
The books provide knowledge.
They do not change who he is.
This is how RAG often feels in practice.
The model gains access to information.
But it does not fundamentally acquire new abilities.
Its internal structure remains unchanged.
Its strengths remain the same.
Its weaknesses remain the same.
The training weights have not moved a single bit.
The Scorpion
Eventually I found myself thinking about the famous scorpion fable.
The scorpion crosses the river on the frog’s back.
Halfway across, the scorpion stings the frog.
“Why did you do that?” asks the frog.
“Because it’s my nature,” replies the scorpion.
This is what happens when local models encounter specialized domains.
At first, they use the provided documentation.
They follow the context.
They appear knowledgeable.
But when the conversation becomes difficult, when context becomes fragmented, or when token limits start removing important information, the model begins filling the gaps.
And what does it use to fill those gaps?
Its nature.
Its training.
Its original statistical assumptions.
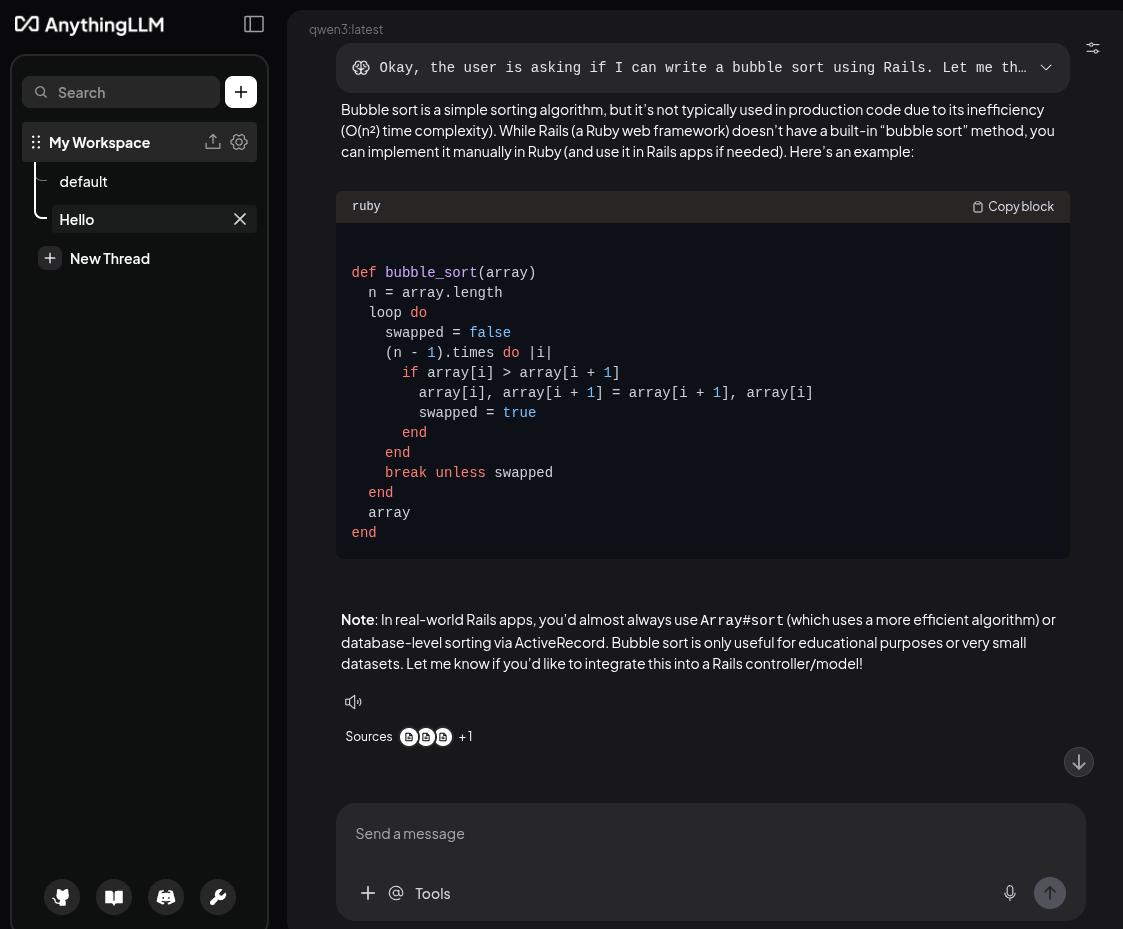
Methods appear that never existed.
APIs are invented.
Classes are hallucinated.
Behavior from completely different ecosystems suddenly appears inside Ruby code.
The scorpion returns.
Not because the model wants to hallucinate.
Not because it is broken.
But because it is operating beyond the limits of what it truly knows.
The Cost of Fighting Nature
One of the most surprising discoveries was how expensive it becomes to fight these limitations.
The solution is always the same:
Add more context.
Add more documents.
Add more embeddings.
Add more retrieval.
Add more tokens.
But every layer introduces cost.
More RAM.
More storage.
More CPU cycles.
More indexing.
More maintenance.
Eventually, a different question emerges.
The problem is no longer finding information.
The problem is getting the model to use that information correctly.
This is where many local AI experiments become frustrating.
The engineering effort grows faster than the quality improvements.
Why Bigger Models Exist
This experience also changed how I think about large models.
I used to assume that larger models simply knew more facts.
Now I think the story is more complicated.
Large models are not only storing more information.
They are also developing richer internal representations.
They have seen more edge cases.
More domains.
More unusual combinations of concepts.
More examples of technologies that smaller models rarely encounter.
In a sense, large models spend billions of parameters trying to reduce the distance between their nature and the problems we eventually ask them to solve.
Conclusion
After weeks of experimentation, I still believe RAG is valuable.
It is one of the best strategies available for customizing model responses.
But I no longer see it as a magic solution.
RAG does not transform a model into an expert.
RAG does not rewrite training.
RAG does not eliminate limitations.
RAG gives the model a memory.
Training gives the model its nature.
And when memory becomes incomplete, the model eventually falls back to what it has always been.
The original sin remains.
And somewhere inside every language model, the scorpion is still waiting.