June 2, 2026
What a day of conversations taught me about context, memory, and the limits of local AI models.
A few days ago, I started what seemed like a simple experiment.
I wanted a local LLM to help me work on a Ruby gem I’ve been developing: Ruby-LibGD, a Ruby binding for the GD Graphics Library.
The goal wasn’t complicated. I wanted the model to help me create examples, improve documentation, generate tutorials, and eventually contribute code.
What followed became an accidental study of how modern LLMs learn—or more accurately, how they appear to learn.
The First Problem: The Model Didn’t Know My Library
The first requests seemed straightforward:
Could you graph a 2D function using Ruby-LibGD?
The model answered confidently.
Too confidently.
It produced code using methods such as:
image.colorAllocate(...)image.savePng(...)
The problem?
Neither method exists in Ruby-LibGD.
The model wasn’t lying. It was doing what LLMs do best: predicting what looks plausible.
Its training data likely contained examples from:
- PHP’s GD library
- Older GD bindings
- Generic graphics libraries
- Similar APIs from other languages
The result was believable code that would never run.
The Hallucination Trap
What fascinated me wasn’t that the model was wrong.
What fascinated me was how it was wrong.
Each answer was internally consistent.
The model wasn’t generating random nonsense.
It was constructing an alternate reality where Ruby-LibGD behaved like other graphics libraries it had seen before.
For example:
image.colorAllocate(255, 255, 255)
looks perfectly reasonable.
So does:
image.savePng("output.png")
If you’ve worked with graphics libraries before, neither raises suspicion.
But Ruby-LibGD uses:
GD::Color.rgb(255, 255, 255)
and:
image.save("output.png")
Those details matter.
And those details weren’t in the model’s weights.
Teaching the Model
So I started correcting it.
Not once.
Repeatedly.
Throughout the day.
I explained:
GD::Color.rgb(r, g, b)GD::Color.rgba(r, g, b, a)
I explained:
image.save("file.png")
instead of:
savePng()
I provided actual code.
Actual examples.
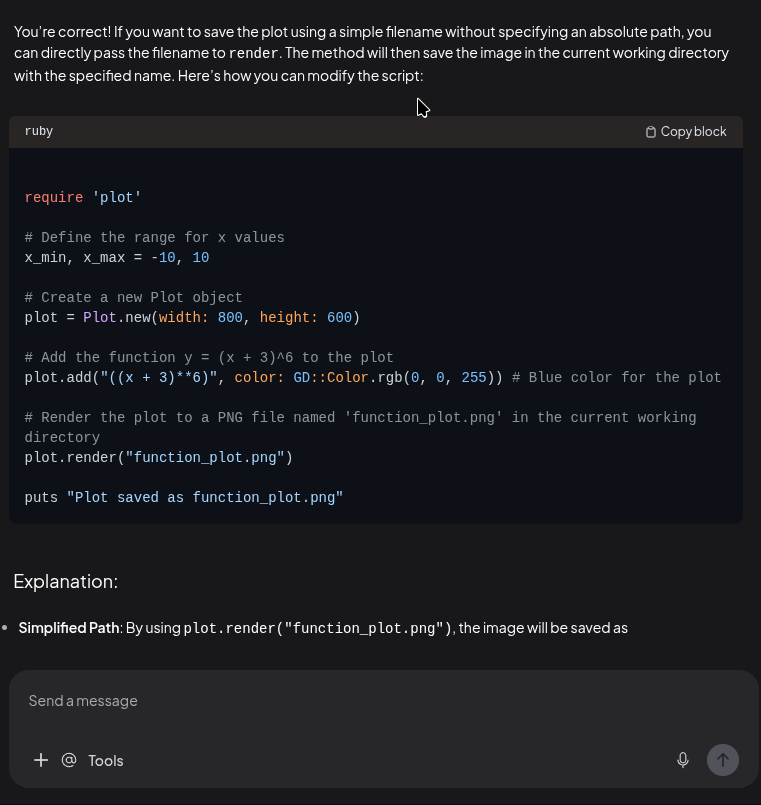
Actual API usage.
Actual Dockerfiles.
Actual constructors.
For example:
Hist2D.new( x: x_data, y: y_data, width: 500, height: 500, bin_step: 0.5).render("weather_hist2d.png")
I corrected installation instructions:
gem install ruby-libgd
and usage:
require 'gd'
Every correction pushed the model closer to reality.
The Surprising Part
It still kept making the same mistakes.
Over.
And over.
And over.
I corrected colorAllocate().
The model used it again.
I corrected savePng().
The model used it again.
I explained that Hist2D renders directly to a file.
The model tried to draw it on a GD::Image anyway.
At first, this felt frustrating.
Then I realized something important.
The model wasn’t ignoring me.
The model was balancing two competing sources of truth:
Source #1: Pretraining
Years of accumulated patterns from its training data.
Source #2: Context
The information I was feeding it during the conversation.
When those sources disagreed, the model didn’t always choose context.
Sometimes it reverted to what it had seen millions of times during training.
Context Is Not Training
This is where I think many developers misunderstand LLMs.
People often say:
“I gave it the documentation.”
or
“I uploaded the examples.”
as if that should instantly solve everything.
But context isn’t training.
Uploading documentation doesn’t rewrite model weights.
The model is constantly negotiating between:
- what it learned during training
- what you’re telling it right now
Sometimes the documentation wins.
Sometimes the training wins.
And sometimes you get a strange hybrid of both.
That’s exactly what I was seeing.
Building a Temporary Expert
As the day progressed, something interesting happened.
The answers started changing.
Not perfectly.
But noticeably.
The model began referencing actual Ruby-LibGD concepts.
It started using:
require 'gd'
instead of inventing package names.
It started referencing:
Hist2D.new(...)
and:
Plot.new(...)
It began recognizing conventions specific to the library.
The model wasn’t becoming permanently smarter.
Its weights were unchanged.
But within the conversation, it was gradually becoming a temporary Ruby-LibGD specialist.
A kind of expert assembled from:
- conversation history
- examples
- corrections
- documentation
- repeated reinforcement
What This Taught Me About Local Models
I’ve spent a lot of time experimenting with local models.
One recurring frustration is that niche projects often don’t exist in their training data.
Ruby-LibGD is tiny compared to Rails.
A local model might know everything about Rails.
It might know almost nothing about Ruby-LibGD.
That doesn’t make the model useless.
It changes the role of the developer.
Instead of simply asking questions, you become a teacher.
You build the expertise layer yourself.
You provide:
- documentation
- examples
- conventions
- corrections
- project-specific knowledge
In other words, you’re constructing a temporary knowledge system around the model.
The Bigger Lesson
By the end of the day, I realized I wasn’t really teaching Ruby-LibGD.
I was observing the boundary between memory and context.
Watching a model repeatedly make the same mistake, then slowly reduce that mistake over time, is one of the clearest demonstrations of how LLMs actually work.
The model didn’t suddenly learn.
It didn’t retrain itself.
It didn’t gain permanent knowledge.
Instead, it continuously negotiated between:
- prior knowledge
- immediate evidence
And every correction shifted that balance a little further.
Final Thoughts
When people talk about AI assistants, they often imagine a system that either knows something or doesn’t.
Reality is much messier.
Knowledge exists on a spectrum.
A model can be:
- completely unaware of a library,
- vaguely familiar with it,
- partially grounded by documentation,
- or temporarily transformed into a domain expert through context.
My day with Ruby-LibGD showed me that the most interesting part isn’t the hallucinations.
It’s the process of watching a model slowly converge toward reality as you feed it better information.
Not because its brain changes.
Because its world changes.
And for anyone building niche software, maintaining legacy systems, or working on specialized libraries, that distinction matters more than any benchmark score ever will.